- Functional Tensor Decomposition for INRs. We introduce a new paradigm for representation learning that is orthogonal to network design: factorizing a high-dimensional INR into compact, axis-specific sub-networks via established tensor decomposition modes (CP, TT, Tucker).
- F-INR: a modular, agnostic framework. F-INR is both architecture-agnostic (works with SIREN, WIRE, FINER, Factor Fields, ReLU/Tanh ± positional/hash encoding) and decomposition-agnostic, giving fine-grained control over the speed–accuracy trade-off through tensor rank and mode.
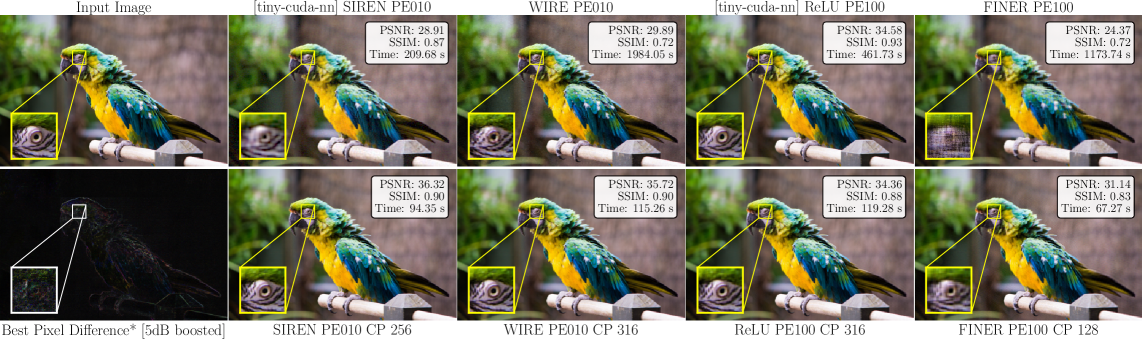
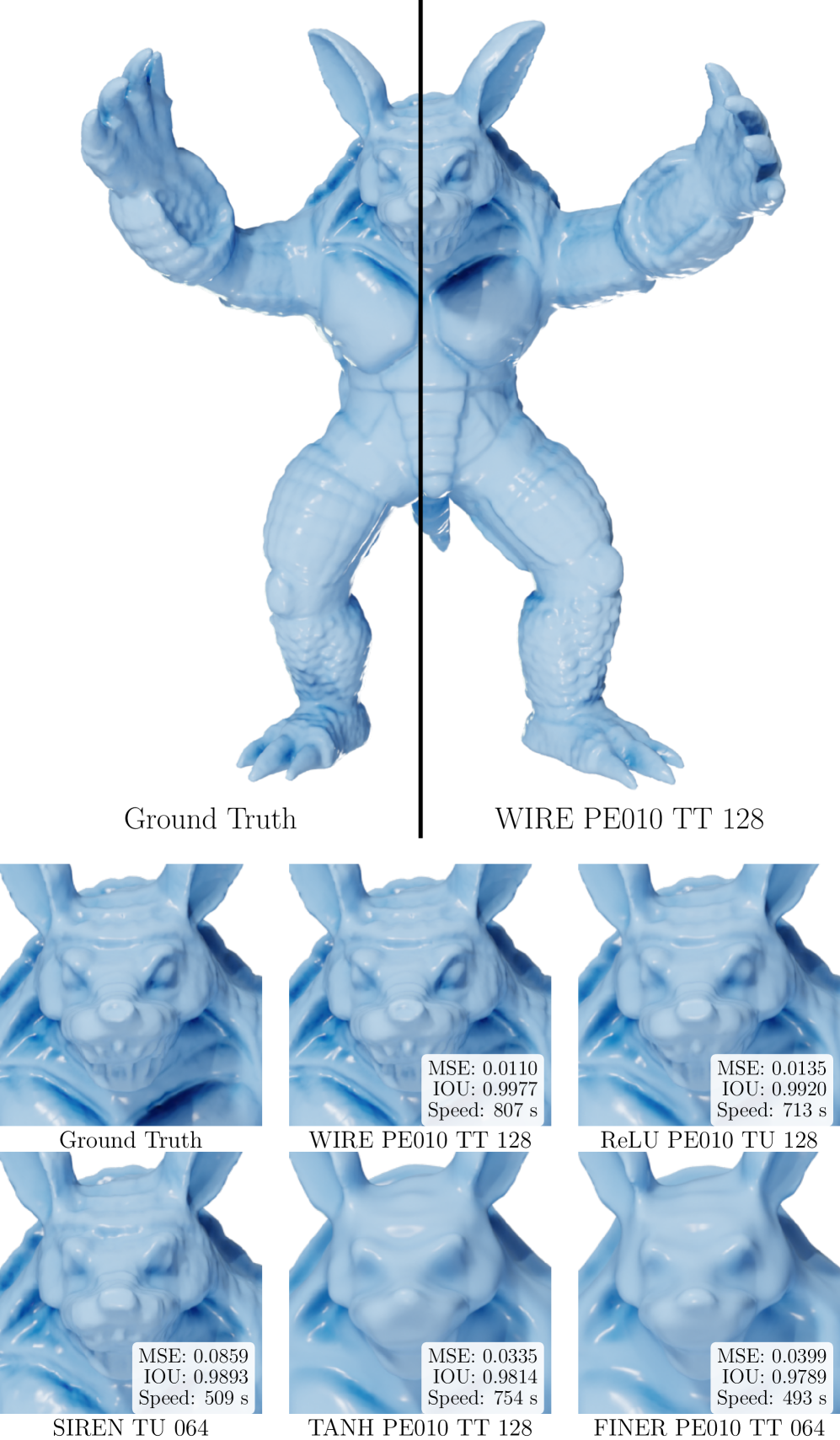
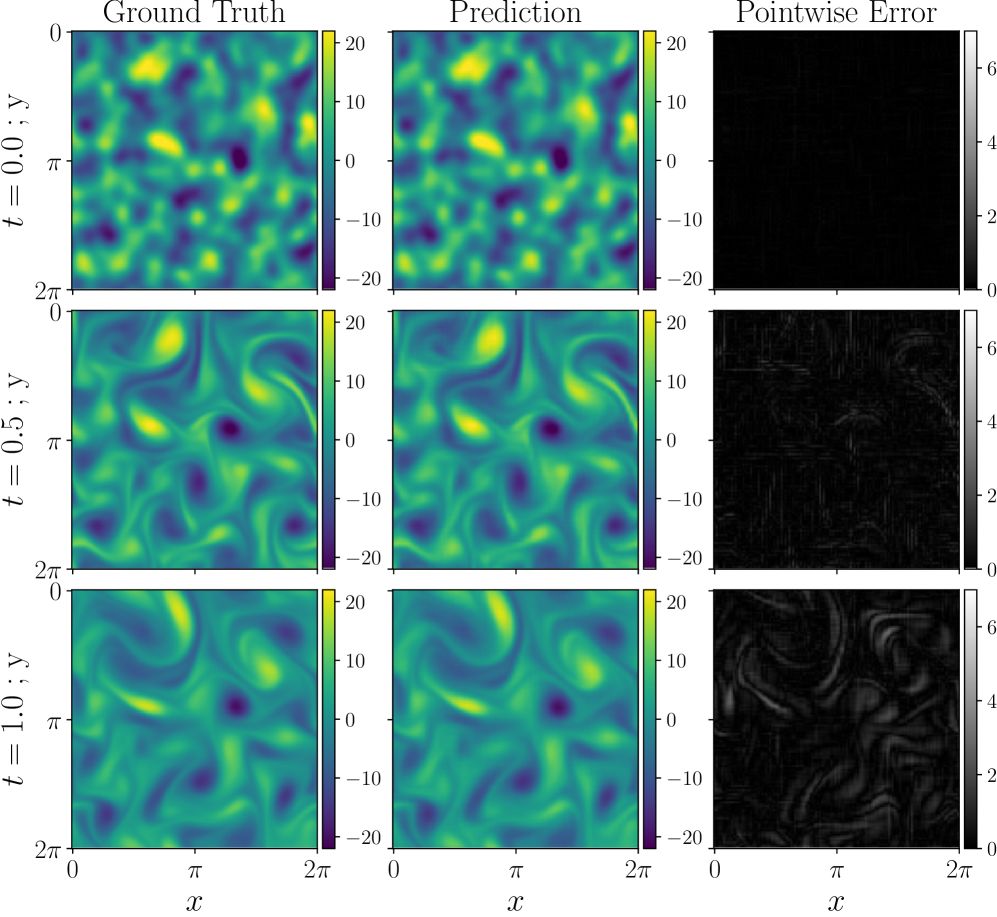
- Significant empirical gains. F-INR accelerates training by up to 20× while improving reconstruction fidelity by over 6.0 dB PSNR compared to state-of-the-art INRs across image representation, 3D geometry (SDF), neural radiance fields, and physics-informed simulations.
Method
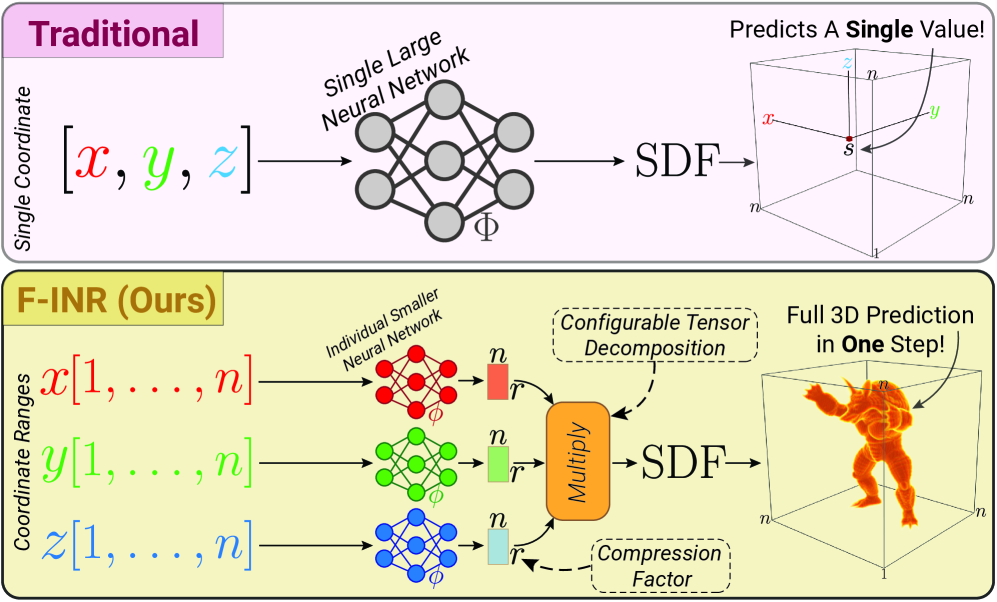
Figure 1: Efficient INRs via Functional Tensor Decomposition. INR models use a single, large network to predict one value (or a batch of values) at a time. Our approach decomposes the function into smaller networks, enabling full prediction in a single step with configurable tensor decomposition modes and compression ranks.
A conventional INR learns a monolithic network \(\Phi_\theta : \mathbb{R}^d \mapsto \mathbb{R}^c\) that maps a \(d\)-dimensional coordinate to a \(c\)-variate output signal. The curse of dimensionality means that the number of parameters, and thus training cost, grows exponentially with the input dimensionality.
F-INR addresses this by replacing the monolithic network with a product of \(d\) small, univariate sub-networks:
\[ \Phi(\mathbf{x}) \approx \bigotimes_{i=1}^{d}\, \phi_i(x_i;\,\theta_i), \tag{1} \]where \(\phi_i(\cdot)\) denotes a univariate neural network for the \(i\)-th dimension with learnable parameters \(\theta_i\). Each network produces a component of particular rank \(R\) to restore the original signal via classical tensor decomposition modes \((\bigotimes)\). The decomposition tensors have continuous functions as bases, yielding functional tensor decomposition; hence the name F-INR.
The outputs are combined via \(\bigotimes\) corresponding to one of three classical modes:
- CP (Canonic-Polyadic) — \(d\) factor networks of rank \(R\), combined by element-wise product and summation.
- TT (Tensor Train) — a chain of low-rank tensor cores; two factor networks and one decomposition core.
- Tucker (TU) — factor networks plus a small core tensor \(\mathbf{C}\) capturing inter-mode interactions.
This reformulation reduces forward-pass complexity (see Table 1), preserves full differentiability with respect to input coordinates (enabling PDE-based objectives), and is backend-agnostic, any INR architecture can serve as the sub-network backbone.
Table 1: Forward Pass Complexity
Assuming a grid of \(n \times n \times n\), i.e.\ \(n^3\) data points, and a network with \(m\) features and \(l\) layers. Note \(r \ll m^2 l\).
| Mode | Forward Pass | Sub-networks |
|---|---|---|
| CP | \(\mathcal{O}(n \cdot d \cdot r \cdot m \cdot l + r \cdot n^d)\) | \(d\) factor networks |
| TT | \(\mathcal{O}(n \cdot d \cdot r^2 \cdot m \cdot l + r^2 \cdot n^d)\) | 2 factors + 1 core |
| Tucker (TU) | \(\mathcal{O}(n \cdot d \cdot r \cdot m \cdot l + r^d)\) | \(d\) factors + core \(\mathbf{C}\) |


{kind=link}